
Kaggle Credit Scoring data science competition
This summer Mooncascade participated in a data science competitionorganized by Home Credit Group, a financial institution that focuses on lending money to individual consumers with little or no credit history. Home Credit organized their competition through an extremely popular Kaggle platform and it turned out to be a humongous battle of 7198 teams. Over a very productive summer these teams together generated ~132k competition entries.
What is Kaggle?
Kaggle is the most popular platform for hosting data science and machine learning competitions. A whole community of kagglers grew around the platform, ranging from those just starting out all the way to Geoffrey Hinton.
In 2017, Kaggle was acquired by Google and integrated with Google Cloud Platform. Now, both the competition data can be hosted in the cloud, and the compute can happen there as well. Kagglers have a possibility to run their competition code on GCP by creating the so-called Kaggle kernels (interactive Python or R notebooks), which make it possible to share code and submit competition entries.
Kaggle already hosted other competitions organized by the financial sector companies: forecasting stock movements based on news, predicting value of a transaction for a customer or predicting real estate value fluctuations. Financial data is most often tabular in nature. Recently, image classification and segmentation competitions were outnumbering the ones based on tabular and time-series data: pneumonia detection on X-Ray, working with satellite imagery, seismic images, or just ordinary photographs.
The competition organized by Home Credit ended up being incredibly popular and by the number of competition entries it was the biggest competition ever on kaggle (by the number of participants, it’s second only to the playground challenge on predicting the survival on Titanic, which is a very romantic, but completely moot problem).
In fact, the Home Credit’s competition might right now hold the status of the biggest data science competition ever, if we consider the fact that Kaggle’s counterparts are not nearly as popular. CrowdAI focuses more on academia (e.g., for NIPS benchmarks) and governmental institutions, startcrowd.club and drivendata.co are focusing on companies, and all of them combined do not attract nearly as many participants as Kaggle does.
Credit scoring
Home Credit offered to kagglers a problem of credit scoring (predicting the default risk for a loan). More precisely, Home Credit wanted us to predict, whether a client would delay a payment more than X days on at least one of the first Y installments of the loan, where both X and Y are some undisclosed positive whole numbers.
Home Credit’s target group are individuals, who have difficulties getting a loan from a bank because of their problematic creditworthiness (which could boil down to something innocent, such as an absent credit history). To mitigate the risks when stepping into this grey area Home Credit uses other sources of information: data from the telcos, financial transactions, and even social media. All this data, after careful anonymization, was shared with the competition participants.
The default solution for the credit scoring problem are credit bureaus (aka credit reporting agencies) and credit rating agencies, which operate in almost every country. Credit bureaus deal with individual consumers and cater to the banks, while credit rating agencies deal with debt obligations of the companies and cater to the investors. In this competition we were only concerned with the private borrowers and a very helpful and important part of the information came from a credit bureau. Credit bureaus collect data from the banks, landlords, retailers, then aggregate and process this information and sell it back to the banks in a form of a credit score. Home Credit bought three credit scores from different agencies. In addition to the scores, they also bought the information that these scores were based on — a complete credit history of each customer during the past 8 years.
Different countries, different rules
Credit scoring works a little differently in each country, and credit bureaus estimate creditworthiness based on different information, if such a bureau exists in a country at all. Usually, credit scoring is heavily regulated to protect both the lenders from the risks and the borrowers from unfair discrimination, and the type of data and algorithms that can be used is restricted (to ensure both fairness and interpretability).
In US, UK, Canada building a good credit score means essentially taking and successfully repaying loans. However, in many countries positive information is not taken into account at all, only bad debt matters. For instance, Bank of France maintains a database, which provides information about persons who have a substantial delay on repayment, or have defaulted on their loan, but does not store any information on successfully repaid loans or spotless credit card usage history. In the Netherlands, Spain, Portugal the system is similarly focusing only on negative information.
In Germany there is one major source of credit information, a private credit bureau SCHUFA, which provides both positive and negative information, based on a comprehensive list of sources, including utility bills and rent. In many countries there are several credit reporting agencies and the score can be compared between them, moreover, the agencies can be both private and public.
How many years of credit history are stored and reported also differs per country. In Australia, only 2 last years matter, but in some countries, once you’ve defaulted on a loan, you’d have to wait as long as 6 years for it to clear (e.g., Spain).
Competition data
Though Home Credit operates in multiple countries in Europe and Asia, and also recently started their business in USA, their most active market is in Asia and CIS countries. We do not know, which country the data comes from, but there are some indications (number of credit bureaus, retirement age, specific variable names like “fond kapremont”) that the data might be from Kazakhstan or Russia. It might also be that the dataset is a combination of data from several countries, for instance, Kazakhstan, Russia and Ukraine.
One of the factors which probably made this competition so popular was the fact that it’s a small data competition: ~350k loan applications (Home Credit has 56.5 million customers, and again we don’t know, how the data was sampled). Being only 2.5 Gb in size, this dataset fits nicely into memory.
The personal financial situation of the client was thoroughly described: income, family size, car age, type of housing and the average properties of the house where the client owned an apartment, last mobile phone change, and even the observed number of defaults in the social circle of the client. A very valuable part of the information were loan applications (both approved and rejected) that the client had previously had in Home Credit. Most of the customers were returning customers, who either previously obtained credit or opened a credit card with Home Credit. In addition, a complete credit history was bought from a credit bureau.
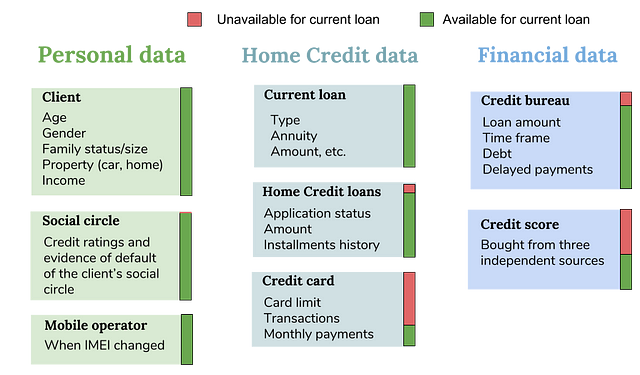
In reality, though several sources of data are available for most loans, there are many missing values in the 210 variables of the dataset.
Our solution
Mooncascade decided to participate in this competition partly because credit scoring and financial data science is an area of interest for us, and partly as a team-building exercise for the developers interested in data science related projects. Another aspect was to help develop internal talent making their first practical steps in Data Science field. Though it was the first Kaggle experience to some in our team, in the end we achieved the results we were happy with and scored within the top 8%, and definitely learned a lot about kaggle competitions, which are a quite different world from real life business needs.
Data cleaning
The major obstacle with this dataset was noise, missing values and inconsistency in the data. Credit bureau data was very low quality. 85% of the clients in our sample had some credit history. Both negative and positive history was reported. For 55% of the credits the information about the payment history was not provided, and, unfortunately, this information was essential.
According to payment history, a realistic 12% of the clients experienced payment delays of at least one month, but according to the overview table, only 0.002% of the clients had delays. Therefore, for around half of credit bureau data, where payments history was not provided, we cannot reliably see, what happened to the loan. It was even hard to establish, whether it was eventually paid off or not. For instance, for some loans the status would be active, but the actual end date has passed long time ago and information is more than a year old. Sometimes, the statuses in the installments history and in the loan information would not match. We tried to clean this data as best we could by combining information from several columns to reconstruct the picture.
The data about Home Credit’s own previous loan applications was a bit better quality, structured in the same way — loans application, monthly balances and installments, if the loan was approved. Most of the clients were returning customers. The default rate in this sample was about 8%. Home Credit also bought an independent external credit score of each client, though for 64% of the clients at least one of those scores was missing.
In order to combine the credit history with the application data, we computed features separately on groups of loans (active loans, completed loans, consumer and revolving (credit card) loans, etc.). Then all sorts of aggregations were applied to the data, which resulted in ~4k features, from which we selected about 1200 best features.
Imputing the missing values didn’t give an improvement. However, for one of the teams, predicting external credit scores gave a small improvement. Another popular way of dealing with this noisy dataset that other teams used was applying denoising autoencoders to the features.
Feature engineering
The dataset had an immense potential to be improved by skilled feature design. We started with the simple things: computing the length of the loan, annuity relative to income, down payment percent. We also computed, how often was the installment calendar rescheduled and whether it was increased or reduced, whether loans were paid out in advance, how regularly the client took loans, and overall loan burden on the client.
The more recent history is more important, so we separately computed features for the recent history and for the previous years.
One of the important features was interest rate, because it hints at the risk that Home Credit’s model assigned to a particular loan. The interest rate was not given for any of the loans or credit cards (also not for the Credit Bureau loans), but it was possible to estimate it for some loans. Another interesting approach from the team that earned the 5th place was to combine user historical data into an 89×96 matrix of real values and training a neural network to extract features from it. 89 were different features (installment amount, loan application amount, transactions) and 96 were the number of months (we had the data for the last 8 years before current application).
There were many categorical variables in the dataset (applicant’s profession, loan purpose, product type etc.). For the low cardinality features we used one-hot encoding, for high-cardinality features we used target mean coding with smoothing.
Model training
The staple algorithm for this type of noisy tabular data are gradient boosted trees. Boosted trees are an ensemble learning method, that uses iterative process to improve each next tree based on the errors made by the previously built trees. The method is prone to overfitting, if the depth of the tree and other hyperparameters are not chosen correctly. We started with LightGBM, then added XGBoost and CatBoost (the latter has an inbuilt capability of dealing with categorical variables). We also trained a neural net, and the bagging type of tree ensemble — RandomForest. The parameters of the models were optimised using Bayesian Optimization.
To create a final submission, we combined the results from individual models weighted by their performance. LightGBM performed best and the neural net worst.
Results
Throughout the competition, Kaggle is boosting the competitive spirit by showing the leaderboard with team places. The leaderboard is computed on a small part of the test set, called public test set. It is not really public, as the labels for it are not shared. But 5 times per day every team can submit their predictions for the test set, and the evaluation metric (ROC in our case) would be computed for the public test set and shown on the leaderboard.
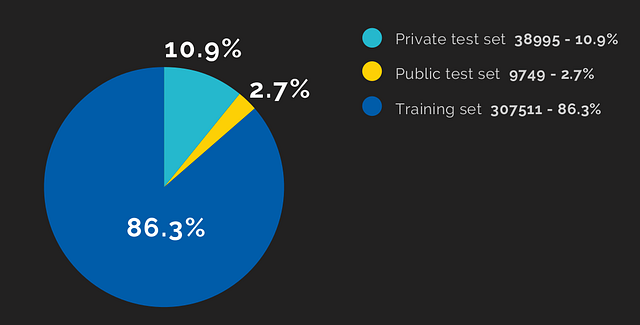
In this competition, however, the public test set was really tiny — less than 3% of the data. We decided to not concentrate on it much, as the difference between the cross-validation score on the train set and the score on the public test set was not big (meaning that there probably wasn’t a big shift in sampling principle and data distribution between the train set and the test set). Some of the teams relied more on the leaderboard score, it was not uncommon to submit a few hundred submissions. We mostly trusted our cross-validation score, and in the end we did not overfit to the public leaderboard score and rose 1339 places on the private leaderboard. Being in the top 8%, we obtained a bronze medal for this competition (shared with other teams). The gold medal and silver medal winners, traditionally already on Kaggle, were merges of several teams. The difference between our solution and the best performance was ~1%: winner’s ROC=0.80570, and our ROC=0.79536. Merging the approaches of several teams, who have worked independently, is always beneficial, because it creates a so much needed variety in features and training, and from less correlated combined results comes smoothing effect, which helps to fight overfitting and unnecessary variance in the individual models.
From Kaggle back to real life
What happens on Kaggle stays on Kaggle.
It is often impossible to implement the kaggle solutions in a business data pipeline due to their hacky nature (being a hideous ensemble model summoned by weeks of hacking). For instance, the interest rate on the current loan is a cheat variable that is not really available during the time when loan application is submitted.
More importantly, in real life, there are many restrictions to what can or cannot be used for credit scoring. For instance, gender or race variables generally cannot be used as model input, probably also not client’s social circle based variables. In addition to that, it would be difficult if not impossible to use black box type model, because in many countries the client or supervisory organizations can require an explicit explanation of the reasons behind model’s decisions. Many of the countries in Asia Pacific, where Home Credit works, are much less restrictive and would allow a black box model. However, the company itself would still want to have some transparency, at least using LIME-type model debugging. Lastly, the number of variables in the number of thousands would not do in a real life credit scoring model.
On Kaggle, the teams also do not need to worry about many things that would be a concern for a model in production: reject inference (dealing with the consequences of each model being trained only on the output approved by the previous model), exploring additional data sources, monitoring variable shift, building data pipelines.
Data Science at Mooncascade
If you have any promising ideas for integrating a data science project into an impactful business, I’d be more than happy to help you think things through — just get in touch via LinkedIn, for example. Mooncascade, the company I work for, is specialized in data science consultation and implementation. That’s how we make our impact!
Initial discussion and the first look by us at your data to spot the potential for high-impact opportunities are both free. After this stage, you could continue work on your own, with other partner(s), and/or with us. The main benefits that come from working with us are world-class data science team, a quality of work, and a sharp focus on positive impact and validating this impact from beginning to end.




