
Applying AI in Business, Demystified
In short, I am writing this post to demystify the topic of AI in business.The field of AI and data science is currently going through an extreme hype cycle. The technology carries enormous promise, but all the noisy hype makes it daunting or intimidating to filter out where the value actually is; and, how to make use of the existing AI components that are already easily available and accessible.
To illustrate the hype situation — within one week in August I visited 2 conferences in Toronto, one was IT-centric and the other was FinTech centric, both of them were talking, almost exclusively on two topics: blockchain and AI. There was almost nothing else discussed. The only difference was that the presentations and speeches at the IT conference were 2/3 on AI and 1/3 about blockchain, while the FinTech conference presentations were reverse.
While everyone is talking about AI as the next leap forward in business and people’s lives the natural emotional questions for most business leaders at all levels are the following:
- How does my organization make sure we are not missing out on something important that continues to pick up speed?
- How can I embrace these new technologies so they bring high-value impact to my company without risking too much money or other valuable resources and energy in the process?
In this post, I will be making an attempt to outline a real strategy for success in AI and data science by separating out the emotions of hype. I will attempt to lay this out in a simple to understand research and development process for a successful AI or data science project. It will be based on the hard lessons learned from many projects.
1. Clarifying the Big Terms: AI, Data Science, Machine Learning, Big Data, … or What?
Before getting to the business case driven research and development process, I will try to clarify “The Big Terms” a bit so we are all on the same page. There is lots of buzz around each of these techy them, but don’t let yourself be intimidated or carried away by those. Especially because those often mean different things to different people, because of heavy hype and overuse.
Artificial Intelligence (AI)
You may have noticed me use the terms AI (artificial intelligence) and data science interchangeably above. I did it deliberately. AI as a term seems to be present in lots of hype while talking about data science applications, it is an attention grabber, it has a certain coolness to it, evoking us feel like we live in the brink of a sci-fi world. But technically speaking, “AI” is a rather fuzzy term, with no clear boundaries, a kind of catch-all for every discipline that makes machines to look and behave (somewhat) intelligently.
Data Science (DS)
This term is the youngest in the family. It refers to anything that involves data analysis and algorithms, especially the science behind them: big data analytics/data mining, machine learning, statistics, mathematics, information and computer science.
Is it AI or DS then?
From now on, in this post, I am going to stick more with the term “data science” for the “all-combining” purpose.
Some wise person (I don’t recall exactly who that was) said once that as long as something is called AI, we’re dealing with “science fiction”. But as soon, as it’s implemented in real life, it becomes just a “computer science”, not AI anymore. This might explain why AI always seems to be about future rather than past or even present, though much of what we already use in our everyday lives would have certainly been considered sci-fi stuff just ten years ago.
Probably for the same reasons I personally use the AI term when I am in a playful mood with friends, talking about AI singularity, or when in the “salesman mode” 😉 attempting to catch the attention. When I am hacking at home, experimenting, learning, fooling around with Kaggle competitions, or discussing projects and strategies with my team, I talk about and look up for data science.
This applies to naming the teams as well — most likely you would have a data science team work on any of your AI or data science business opportunities. Such a team would consist of data scientists (data science PhD-s who can handle the scientific side of the data exploration, research and validation of the business opportunities), and data engineers, who know how to handle big data frameworks, how to implement the research outcomes into operational environments, etc.
Machine Learning
Machine learning almost sounds like artificial intelligence, but in data science community it’s a bit more concrete and technical term, referring to the specific components or processes in AI that are focused on the learning part of a machine’s intelligence. There are many machine learning algorithms, like (deep) neural nets, decision trees, Bayesian, …, etc, and application areas or data that these can be applied to. The data could be anything, ranging from transaction data to images, videos, audio and vibration pattern analysis, even music, natural language processing (NLP), sensory diagnostic data for predictive maintenance use cases, etc. In essence, these algorithms are all based on some sort of statistical procedures.
Big Data
Though this term has also been much-hyped recently, it essentially refers to any data that exists in amounts too large to be handled or analyzed by “traditional” data handling tools in a single computer, which in turn calls for specific methods for solving problems related to handling heavy loads of data. The heavy load issues could come, for example, from the size of the data storage needed (calling for distributed storage and retrieval systems), or from the need to process information near real-time (call for machine learning methods), etc.
Other terms
There are obviously quite a few more closely-related terms you may encounter when working on this topic, including data mining, big data analytics, business intelligence (BI), etc, but for the sake of brevity, I’ll limit myself to those few boldest ones that decorate the hype scenery today.
2. Setting Up an AI Strategy — the Prerequisite Understanding
Establishing a data science strategy starts with understanding its basic promise, applicability, and limitations.
2.1 The Basic Promise of ai in business
In terms of business, data science is useful for two main reasons. It helps you seek out new revenue streams and helps you avoid losing money due to inefficiencies, fraud, or in human error, and it does so by looking at your data and applying data analytics and machine learning tricks on it.
An example. An online merchant selling digital goods was losing 10% of their revenues due to credit card fraud chargeback requests and penalties, and was being threatened by their payment provider to be shut down if the situation didn’t improve. An AI application involving Bayesian machine learning algorithm was implemented to the merchant’s business and was successfully able to detect 90% of the fraudulent transactions in real-time, with false-positive rate kept below 0.1%. In addition, even though fraudsters were good enough at adapting their behavior so that humanly analyzed and hardcoded fraud-pattern checks became irrelevant just days after the program’s deployment, the machine-learning algorithm in question was able to learn new patterns in near real-time, maintaining its efficiency despite evolving forms of fraud.
2.2 The Applicability of ai in business
The good thing about data science is that its main forms of implementation strategy are rather agnostic to the field that you apply them onto. Wherever you have data piling up or streaming around, there is a good chance you have untapped opportunities hidden there for huge positive impacts.
A top-caliber data science team is usually able to handle any type of data in the same fashion, whether dealing with transactions, images, videos, audio, vibrations, natural language text processing, etc. The applications with a significant business value based on these data could include credit scoring, fraud detection, image recognition, predictive maintenance, natural language processing (NLP) chatbots, intrusion detection (in cybersecurity), conversion and churn predictions, to name a few.
An example. A big industrial company with a network of hundreds of suppliers had its top-level management burdened by non-stop communication with suppliers, to address questions that couldn’t be left unanswered or unsolved. A successful NLP-based chatbot implementation was able to solve and remove 80% of that burden from the company’s top-level management team.
2.3 The Limitations of ai in business
So far it all looks like an ordinary software project, right? Just some bit of a coolness thrown in with the touch of AI and that’s it? Wrong!
Here comes the thing that sets data science projects significantly apart from average software projects, that makes it extremely messy and almost certainly your time-and-money-wasting project if you don’t beware its limitations, and, on the other hand, makes it nicely controllable successful contribution to your business strategy, if you take the difference fully into account.
The significant difference between a data science project and an ordinary software project is rooted in its main limitations:
1. The nature of probability:
In the context of business use cases, machine learning algorithms work through probability, not determination. You will always have the question of accuracy when taking its answers into account. Remember the fraud detection example above — there will always be some amount of “false negative” and “false positive” outcomes, but detecting 90% of fraud (which translated to 9% revenue loss) still put the company in a significantly better situation, removing the risk of having its payment provider discontinue service, avoiding significant losses, and, for the greater good, making the day harder for fraudsters — even at the price of losing some less than 0.1% of the merchant’s legitimate transactions.
If your business case has zero tolerance for “false” answers, you simply can’t apply these methods. However, if your business case can work with accuracy that’s “good enough,” then it simply becomes a question of achieving it.
For example, in a very extreme case of self-driving cars, where you have cascades of AI components in play, one might ask how it is okay to have errors there!? The answer is that there may be “errors” (in machine learning terms) in the system’s sensory real-time data analytics, but these can be narrowed down to individual components in combination with the application of certain robustness principles — which call for never relying on a single data source or sensor — in such a way that these errors won’t cause danger to anyone’s property or health.
2. The question of do-ability:
Data science’s probabilistic nature leads to another important question: even if your business case is capable of accepting some “false” answers in course of actions, is the “good enough” level of accuracy achievable at all? You could develop the entire framing software that integrates your machine learning algorithm seamlessly into your operational environments, it scales etc, but if the ML algorithm is really unable to make decisions with the accuracy that would make sense for your business case, then all the product development around it would be a waste, if not even counterproductive.
And that’s a constant reality of data science projects — the necessary accuracy is not always achievable (at least not on the first try).
A successful data science strategy makes sure these two key aspects are always at the center of any project planning.
3. The Process
Having laid out the above notes, what follows is actually quite simple and straightforward.
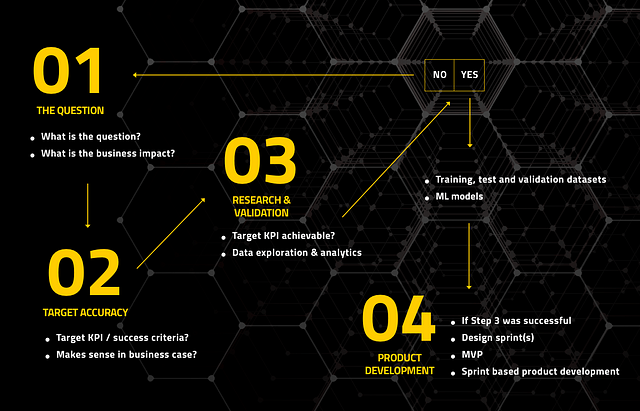
Step 1: Ask “The Question”
At the heart of any data science project is the established question you want your system to answer. When you think about your first (or the next) AI application, make sure you know exactly what question you’ll be answering, and be certain it has a clear link to your business impact.
Examples of the questions:
- Question: Can we predict fraud in our insurance applications? Can we adapt to fraud pattern changes in real-time? Impact: Avoid losing money to fraud.
- Question: Can we detect dangerous goods (radioactive material, weapon components, etc.) being smuggled based on analyzing the related documentation, logistics information and x-ray scans of cargo in seaports and airports? Impact: A safer community to live in.
- Question: Can we predict the mechanical malfunctions before a system actually breaks? (This is called a predictive maintenance question, and could be answered, for example, by listening to audio sensors attached to the body of a machine and analyzing the changes in vibration patterns and harmonics.) Impact: Avoid mechanical malfunctions and revenue loss, even damage costs, that may incur from it otherwise.
Step 2: Determine what “good-enough” accuracy will mean for you.
Once you’ve established your project’s question — but before starting to pour money, time and other resources into heavy development work — it is important to determine how good you’ll have to be at answering this question in order for your business case to make sense. In other words, you’d need to quantify for your system some kind of a Key Performance Indicator (KPI) target that makes sense in the business case.
A simple example: A monthly payment based business with hundreds of thousands of subscribers was continuously losing revenue due to some customers failing to pay their next monthly bill. The question was: could we predict those missing payments in advance? The impact of answering the question was to be the company’s ability to apply the preemptive measures. The KPI target was that it needed to be able to predict at least 75% of the customers who would miss their next payment without a significant false-positive rate, in which case it would make sense to implement the product within the company’s given budgetary limitations.
Step 3: Data Exploration, Research, and Impact Validation
Up until this step in the process you don’t spend almost any resources, other than some basic work to identify the question and establish the KPI target that makes sense.
Now the critical question is: can it really be done? Can your question be answered with a level of quality that will exceed your minimum KPI threshold? This is the business impact validation step. Its aim is to identify all the relevant data sources, explore, manipulate, restructure and tidy up the data, work out the machine learning models, etc. that would be able to create the impact. The outcome of this step includes training, test and validation data sets, which allow you to demonstrably confirm the doability of your product before the actual software product development for it even begins.
By using the term “demonstrably,” I’m referring to the repeatability of the process according to scientific standards and qualities — remember, we are dealing with data scientists (often PhD-grade) at work, with an emphasis on the word scientist. One of the key qualities of the scientific method is repeatability. This means that, technically, the outcome of your research and data exploration includes all of the exact steps, scripts, and data dictionaries showing exactly how the data was obtained, transformed, and divided into training, test and validation datasets, the machine learning model(s) and demonstration instructions.
As you can imagine, this is the first step where it becomes necessary to invest some initial resources, given that research and data exploration are efforts that need to be performed by people who, in turn, have invested heavily into building up their competencies. Still, this is usually kept quite lean and mean compared to the product development project, that follows. The idea here is to avoid investing in product development as long as the project’s do-ability is still up in the air. Investing in product development only makes sense once the research has validated the impact. You would need to be willing to risk investing into those validation cycles, applying reasonable money management methods and per-project stop-loss decision-making strategies to your funds. But, unless you enjoy messy corporate roller coasters, you shouldn’t risk investing in product development before validating your business impact in data speculations.
When research fails to validate the speculated impact during initial sprint cycles, there could be a couple of reasons why:
- The data you’re working with could be just too shallow or lacking in easily discoverable and meaningfully applicable signals. In this case, it’s good that you haven’t started spending resources on the product development and you can begin looking for other ideas to make an impact with.
- It could also be that the relevant signal is evident in your data but it is resisting crossing the expected KPI target threshold that would allow you to validate the business case. In this case, you can speak to your data science team and discuss the possibility of building up more data features that you don’t have yet. This could mean taking a couple of months to have your existing products, those generating the relevant data, store more information about the data being observed, after which you could try your research again and see if the KPI target in question is achievable.
Step 4: Product Development
Once your research in Step 3 has been successful, develop the appropriate data product around the results in such a way that it seamlessly integrates into your operational environment, scales, and makes you capable of creating the real impact.
This stage looks more like a regular software product development. Here you would apply the same principles, starting from the ideation and design sprints (if UI interactions are involved), to validate that the target users are going to grasp the new product and embrace the idea. You would then develop your first MVP (the Minimum Viable Product) to further validate you’re on the right track, now with hard evidence from the field, and iteratively continue developing your product and adding impact to your business case.
As long as the product stays relevant, you’ll typically always have something to improve. In addition to regular software development part of the product, you’ll keep monitoring on the performance of the data science part of the product, occasionally revisiting research cycles to either troubleshoot changes in the data sources or strengthen/optimize the impact of the outcome.
4. The Big Picture
Hopefully, the process layout above can shed some light on ways on how you can start with bringing a data science on board your company. In real life, as successful products go, there will be more continuous nested development cycles going on one after another, and principles you’ll apply to carry them out will evolve as you learn and familiarize yourself with the subject. Still, the essence for a thriving data science project remains the same: the successful data science product is a product of a research-first project, and the successful data science product pipeline strategy is based on such projects.
The main driver of the success is essentially maintaining these two principles throughout the process, never forgetting these at any steps:
- Be sure that you always know what the impact you are looking for will be. Be certain that what you do is actually significant, having a positive impact. This is a fundamental rule for anything to survive in the business context — not just data science.
- Validate the critical assumptions as early and as often as possible.When working with data science projects, validate that the needed accuracy in answering the established question is achievable at the levels for the impact to make economic sense.
5. Where to go from here?
If you’re a successful entrepreneur, you probably already know that most of the big things have started from a myriad of experimentation. It is not different in the data science field either. Here are a few hints for recognizing data science opportunities.
It is generally a good idea to maintain a habit of brainstorming for new, exciting ideas — no matter what field you may be working. So spend some time regularly thinking about your business as well as the work you put into it, and remember that good product ideas can emerge from the most painful problems.
The kind of issues that best lend themselves to be resolved with data science methods are, as the name suggests, those where data can be analyzed with scientific rigor. As mentioned above, the data in question could be anything: transactions, images, audio signals, natural language texts, video clips, temperature fluctuations, other environmental sensory data, and so on.
When coming across a potentially interesting (impactful) idea, start thinking about quantifying its impact (remember KPI target), what kinds of data do you have that can be analyzed, and the ways in which you could validate your speculations.
Mooncascade
If you have any promising ideas for integrating a data science project into an impactful business, I’d be more than happy to help you think things through — just get in touch via LinkedIn, for example. Mooncascade, the company I work for, is specialized in data science consultation and implementation. That’s how we make our impact!
Initial discussion and the first look by us at your data to spot the potential for high-impact opportunities are both free . After this stage, you could continue work on your own, with
Mooncascade data science team just recently got a top-caliber result in a credit scoring contest on kaggle.com, the worlds most popular data science competitions site — we got positioned at top 8% among more than 7000 contestants, and our result was just 1..2% less precise than the winners.




