
Machine Learning vs Deep Learning – When Do You Need An Expert?
If you run a business and you’re interested in using data science tools, you may be wondering what you need to get started. Should you hire a data scientist with a PhD and the salary to match? Or can your existing software development team handle the workload with some extra training?
The short answer: it doesn’t matter whether you choose Machine Learning or Deep Learning. For simple, narrow use cases, you don’t need an expert. There are plenty of Machine Learning and Deep Learning frameworks with pre-trained models that software developers can use right out of the box with some parameter tuning. For more complicated use cases—where pre-trained models can’t be applied and research is necessary—it’s best to find an experienced data scientist.
To help you make the right choice, here’s an overview of both, along with a rundown of some of their costs, benefits, and limitations.
What is Machine Learning?
Simply put, Machine Learning (ML) is a form of statistical data analysis. It allows you to approximate a function for predictions, classification or clustering based on previously collected data. Data is fed into the ML model, which then becomes better at predicting, classifying or clustering over time.
Say you had a record of the cost of utilities in your apartment for the previous year. A machine learning algorithm could use this data to estimate the bill for the coming month relatively easily and accurately. However, if you only had data for the half of the year that includes summertime, then your ML function wouldn’t know how to make accurate estimations for the coming winter. Giving the function a few years of data would solve this problem and it would eventually learn how utility bills vary over seasons.
Machine Learning: can anybody do it?
Machine Learning is made up of a huge variety of algorithms and architectures, including simple linear regression algorithms, Gaussian naive Bayes classifiers, and K-Means clustering methods. In order to use any of these properly, you need to know which problems you can solve with each, and apply them accordingly.
Regression could be applied to financial data, for example, and used for something like credit scoring to predict how much money you could loan to a customer. If you were concerned with suspicious activity in your financial data (usually fraud), clustering could help divide your customers into groups based on the similarities in their behavior. You wouldn’t need to provide any labels or pre-define any classes for a case like this one, as it would constitute a form of unsupervised learning.
Machine Learning requires a solid understanding of statistics. If you’re familiar with terms like “data distribution,” “mean,” “median,” and “standard deviation,” however, you’re off to a good start. Most engineers with a bachelor’s degree in computer science have enough knowledge of statistics to do this. Of course, there’s always plenty left to learn about existing frameworks, data cleaning, and optimization. Be prepared to invest time into understanding why your data behaves as it does, which parameters impact it, and which features are going to be relevant to your use case.
In other words, software engineers and analysts are capable of working with ML. They might lack an understanding of your case’s domain data, but this can be obtained relatively easily. In fact, I recommend training your developers and analysts to think in terms of ML even if they’re not writing ML algorithms on a daily basis. It’ll help make your development and business processes as a whole more data-driven. Once you start thinking in terms of ML, you’ll be basing your decisions on factual data that you’ve collected and analyzed. This is more or less what business analysts do for corporations, but it’s an approach that can be used in any field, by any company, to close the gap between engineers and business people.
So when do you need data scientist and data engineers?

Don’t get me wrong: simple ML may be accessible to software engineers and analysts, but there’s a big difference between simple and complex forms of ML. In simple cases, the data you have access to is useable as is, and the output you expect can be directly produced by an ML function. In most real world applications, however, that simply isn’t the case:
- Data is rarely ready for an ML application. Multiple transformations and standardization procedures are required to make it useable.
- Classic ML approaches are often combined with automated pipelines. For example, one function will clean up the data, another will standardize it, then the data will be transformed and visualized. The data then has to be clustered via different methods and parameters and the results of each experiment put into a log for review.
- Entire systems are built to launch experiment sequences and document the results to test which models and hyperparameters perform best for specific use cases.
- A large amount of visualization has to be applied for you to be able to look at data, explore it from different angles, and see if the results make sense.
- On scale, you need a powerful data warehouse and you need to ensure its data is accessible. You also need to provide fault tolerance mechanisms to avoid failing experiment sequences, to automatically balance loads for different experiments, and to guarantee data security.
In any of the above cases, you’d need to get professional data scientists and data engineers involved for your project to succeed.
What is Deep Learning?
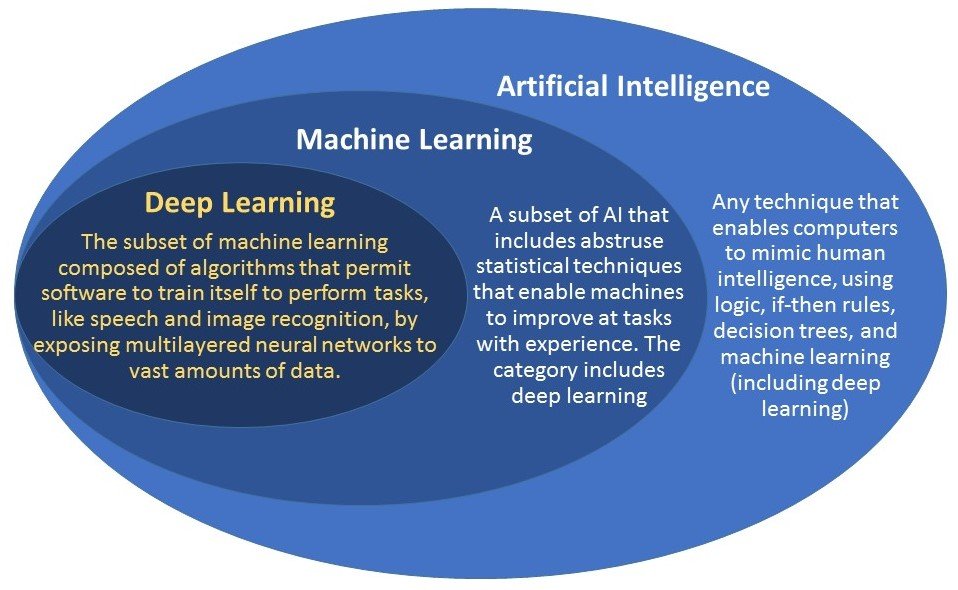
Next up is Deep Learning (DL). DL is a subcategory of Machine Learning that uses architectures like deep neural networks and deep belief networks. The “deep” in DL refers to the number of layers neural networks contain.
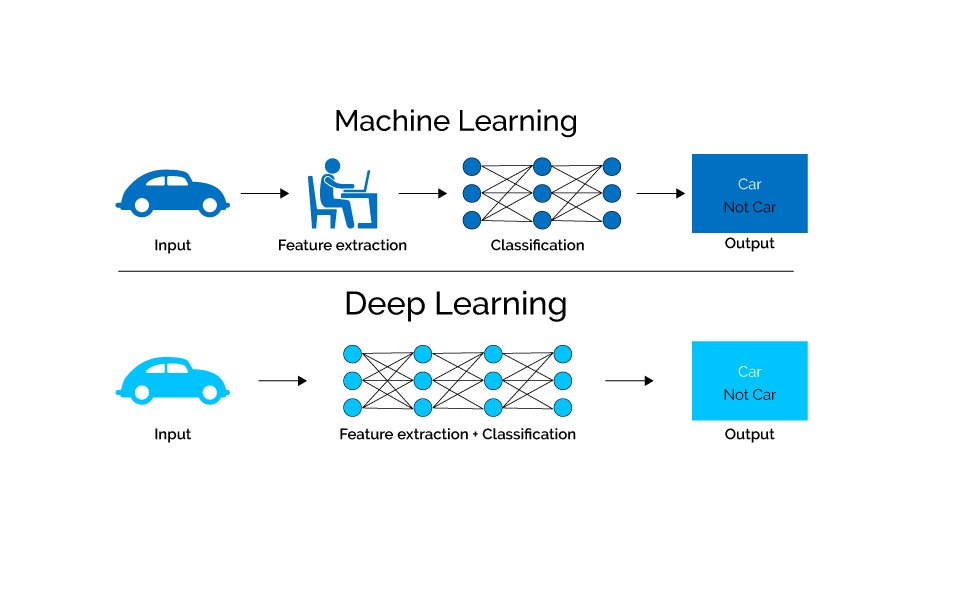
Deep Neural Networks (DNNs) are very good at solving specific tasks when given enough data. Nowadays, they’re a state-of-the-art technique for carrying out natural language processing, speech recognition, machine translation, and computer vision. Products like Alexa, Google Assistant, FaceID, and anything that involves smartphone camera enhancements are made possible by Neural Nets.
The best part of using neural networks is that you don’t have to decide which data features you’d like to use beforehand: just set a goal, provide the model with a huge dataset, and the network will learn which pieces of data to consider relevant on its own when calculating the final result. You may have to tweak some parameters or try different neural network architectures to improve the model’s accuracy or speed.
When comparing Machine Learning and Deep Learning, you have to take their similarities into account alongside their differences. ML and DL are both trainable algorithms that get better at predictions and classification with more data. They both have a certain amount of issues with underfitting and overfitting, and both need a meaningful loss function defined in order to work properly.
The biggest difference between the two is that DL lacks interpretability. Complex neural networks are capable of competing with humans in certain tasks, which means that they’re better at performing machine learning techniques. However, since neural networks decide what meets your goal by themselves, it can be hard to tell if they’ve understood the principle behind it or are just cheating very well with the given dataset. You can’t immediately determine which data features were considered to be important or why they were chosen. For example, a neural network being used for credit scoring might decide that the current home address of customers in a dataset is a more significant feature than historical data about their loan payments from two years ago.
Deep Learning nuances

In general, neural networks require specialized, labor-intensive skills to be used effectively. You need to know how the network’s architecture works and be ready to collect plenty of data—usually far more than for classic ML models. Your dataset also needs to be properly balanced. If your dataset contains two images of cats and a thousand images of dogs, for example, the neural network will always answer “it’s a dog,” because the chances it has of being wrong are 0,2%.
Your dataset has to be cleaned, too. Since people collect datasets and annotate them, there’s always room for human error. To avoid having the neural network make mistakes as well, it’s important to carefully eliminate errors from the data you input while training the model (i.e., calculating its weights). This means that your datasets have to be both balanced and clean enough for each case to be processed correctly.
Another important point to remember is that neural networks require very thorough testing. You never know how DL algorithms will behave with new data. Each set of parameters you adjust when testing will also require the re-training of certain network layers—if not the whole network—which can affect the accuracy of your results.
There can also be issues with tradeoffs in speed vs. accuracy when using DL. Determining which one to choose often comes down to business priorities—is it better to make quick decisions with a higher margin of error or to avoid error as much as possible, at the cost of taking time for calculations?
Cleaning data, defining and running multiple experiments to find the right parameters, and understanding the model’s errors and output aren’t easy tasks. If you want to properly harness DL’s potential, you’ll have to use the services of a skilled professional. Not every data scientist or machine learning expert can handle DL, though someone who has a background in ML and takes the time to understand the domain data and use case together is definitely on the right track.
Machine Learning vs. Deep Learning: choose what’s right for you
Remember that data scientists are specialists, usually with a master’s or PhD, who are capable of doing both ML and DL. You probably don’t need to hire one to build a Naive Bayes model on a dataset with three classes, as this can be done by one of your software engineers or analysts. However, you may need a data scientist to help you visualize the bigger picture, for example:
- To setup infrastructure and data warehousing
- To select ML or DL methods relevant to your business goals
- To establish data annotation and cleaning processes
- To establish automated training pipelines
When considering ML or DL, remember to think about the value it’ll bring to your company and the costs its implementation will entail. You don’t need an expert to perform a task that a human can accomplish in ten minutes. Unless you need the task accomplished thousands of times per day—that’s when you’d want to replace human labor with an algorithm.
When choosing between Machine Learning vs. Deep Learning, it all depends on the problem at hand. Is your issue solvable with ML or DL? Will DL achieve significantly better results in your business use case compared to classic ML techniques? Is it right for your business to solve a particular use case with ML or DL? What will your investment costs and stop-loss strategy be?
Maybe training your software development or business intelligence team to integrate ML into their workflow is enough. Maybe you need more, but don’t want to hire a data scientist. Consulting with a company capable of building professional-grade ML and DL processes for you could be a perfect solution. Here at Mooncascade, we help companies build smart, cost-effective data science tools all the time, whether they’re budding startups or established corporations.
Interested in applying ML or DL in your business?
The world of ML and DL is full of potential for companies of any kind. If you’re ready to take the plunge but want some advice before you do, get in touch with us today. We’d be happy to help guide the way.




